Zhiwu Huang
 I am a Lecturer (Assistant Professor) affiliated with the Vision, Learning, and Control (VLC) group in the School of Electronics and Computer Science (ECS) at the University of Southampton.
I am a Lecturer (Assistant Professor) affiliated with the Vision, Learning, and Control (VLC) group in the School of Electronics and Computer Science (ECS) at the University of Southampton. I specialize in computer vision and machine learning in the context of artificial general intelligence. My research focuses on improving machine learning by understanding human learning processes and exploring how AI can support and enhance both human life and the physical world. Central to our research team’s mission is the development of happy and green AI—artificial intelligence that is emotionally aligned, human-centered, and environmentally sustainable. Our work advances artificial machine intelligence with generative capabilities in perception, emotion, and action across computers, devices, and robots, with applications spanning healthcare, the arts, and education.
Public Datasets
Open-world Spotting of Diffusion Images Dataset (OpenSDID)
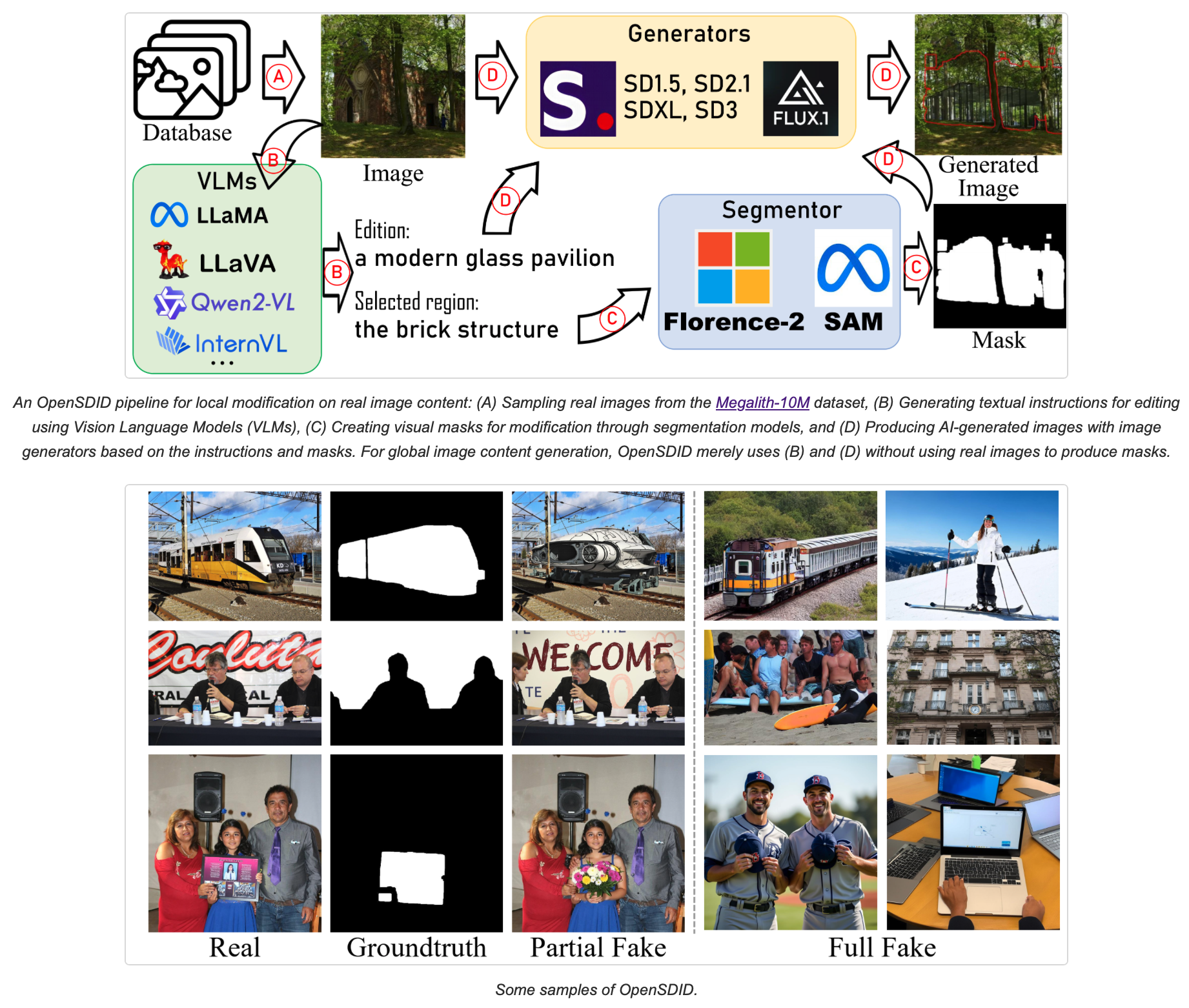 |
This work identifies OpenSDI, a challenge for spotting diffusion-generated images in open-world settings. In response to this challenge, we define a new benchmark, the OpenSDI dataset (OpenSDID), which stands out from existing datasets due to its diverse use of large vision-language models that simulate open-world diffusion-based manipulations. Another outstanding feature of OpenSDID is its inclusion of both detection and localization tasks for images manipulated globally and locally by diffusion models. OpenSDI: Spotting Diffusion-Generated Images in the Open World. Yabin Wang, Zhiwu Huang*, Xiaopeng Hong. (*indicates corresponding author) . In Computer Vision and Pattern Recognition (CVPR) , 2025. Preprint | Project Page | Data & Code |
Continual Deepfake Detection Benchmark (CDDB) Dataset
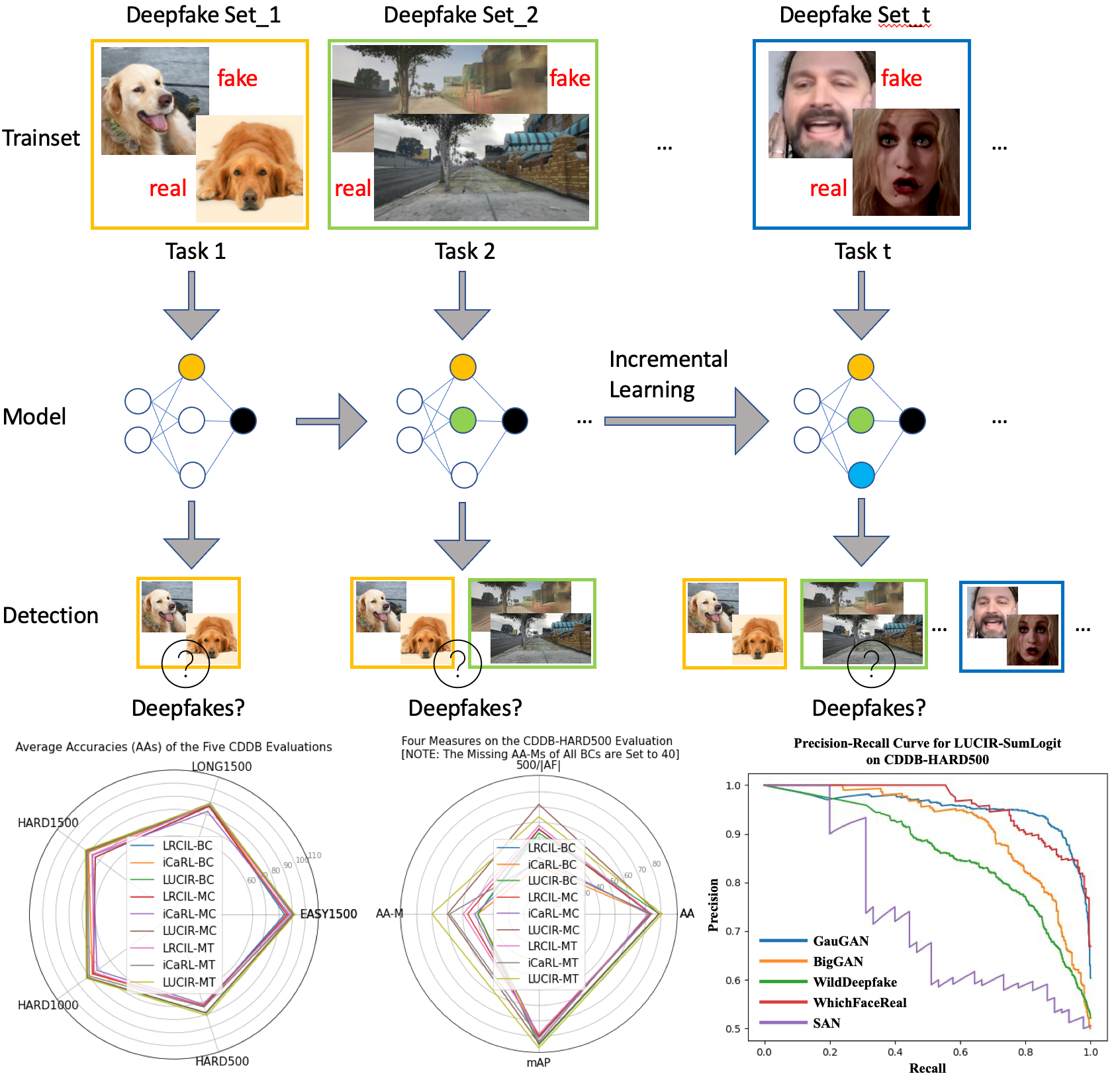 |
There have been emerging a number of benchmarks and techniques for the detection of deepfakes. However, very few works study the detection of incrementally appearing deepfakes in the real-world scenarios. To simulate the wild scenes, this paper suggests a continual deepfake detection benchmark (CDDB) over a new collection of deepfakes from both known and unknown generative models. The suggested CDDB designs multiple evaluations on the detection over easy, hard, and long sequence of deepfake tasks, with a set of appropriate measures. In addition, we exploit multiple approaches to adapt multiclass incremental learning methods, commonly used in the continual visual recognition, to the continual deepfake detection problem. We evaluate existing methods, including their adapted ones, on the proposed CDDB. Within the proposed benchmark, we explore some commonly known essentials of standard continual learning. Our study provides new insights on these essentials in the context of continual deepfake detection. The suggested CDDB is clearly more challenging than the existing benchmarks, which thus offers a suitable evaluation avenue to the future research. Our benchmark dataset and the source code will be made publicly available. A Continual Deepfake Detection Benchmark: Dataset, Methods, and Essentials. Chuqiao Li, Zhiwu Huang*, Danda Pani Paudel , Yabin Wang, Mohamad Shahbazi, Xiaopeng Hong, Luc Van Gool . (*indicates corresponding author) . In Winter Conference on Applications of Computer Vision (WACV), 2023. Preprint |
TrailerAffect Dataset
|
We use Hollywood movie trailers for the dataset collection, which was motivated by the fact movie trailers highlight dramatic and emotionally charged scenes. Unlike whole movies, interviews or TV series, trailers contain scenes where stronger emotional response of actors are highlighted. Furthermore, using trailers of thousands of movies increases the gender, racial and age-wise diversity of the faces in the clips. Approximately 6000 complete Hollywood movie trailers were downloaded from YouTube. Number of SIFT feature matches between corresponding frames was used for shot boundary detection. Approximately 200, 000 shots were detected in those trailers. Concretly, the dataset contains approximately 200,000 individual clips of various facial expressions, where the faces are cropped with 256x256 resolution from about 6,000 high resolution movie trailers on YouTube. We convert them to tfrecord with resolutions range from 4x4 to 256x256. Towards High Resolution Video Generation with Progressive Growing of Sliced Wasserstein GANs. Dinesh Acharya, Zhiwu Huang, Danda Pani Paudel , Luc Van Gool . arXiv preprint arXiv:1810.02419, 2018. Paper |